Качество данных в разработке лекарств: недостающий фундамент для реализации потенциала ИИ в клинических испытаниях
Известное выражение «мусор на входе — мусор на выходе» остается таким же верным сегодня, как и в 1950-х годах, возможно, даже более актуальным в эпоху больших языковых моделей и аналитики на основе ИИ. Хотя искусственный интеллект обладает трансформационным потенциалом для клинических испытаний, его успех зависит от фундаментального элемента, который часто упускается из виду: чистых, высококачественных данных в режиме реального времени.

Несмотря на значительные инновации в отрасли медико-биологических наук, компании продолжают сталкиваться с проблемами фрагментированных экосистем данных. Бремя согласования разрозненных источников данных, часто вручную и постфактум, подрывает те самые результаты, которые призван ускорить ИИ. Чтобы раскрыть весь потенциал ИИ, руководителям клинических разработок необходимо переосмыслить свою стратегию работы с данными с нуля.
Здравоохранение сегодня стало персонализированным, а прецизионная медицина стремится подобрать правильную терапию для конкретного пациента в нужное время, трансформируя стратегии лечения от средних показателей по популяции к индивидуальному подходу. Однако это видение зависит не только от прорывных научных достижений, но и от базы данных, способной собирать и связывать все релевантные сигналы на протяжении всего жизненного цикла клинических разработок.
Поток данных: возможности и препятствия
За последнее десятилетие объем и разнообразие данных в клинических испытаниях резко возросли. Традиционные формы отчетов о случаях из рандомизированных контролируемых исследований теперь дополняются данными из реальной практики, полученными из электронных медицинских карт, страховых претензий, носимых устройств, регистров пациентов и других источников. Эти внешние данные не только могут предложить более полное и целостное представление о результатах лечения пациентов и эффективности терапии, но во многих случаях от них зависят основные и вторичные конечные точки исследования.
На конференции DPHARM 2025 Кеннет Гетц (Kenneth Getz) из Центра клинических исследований и диагностики заболеваний Университета Тафтса сообщил, что в среднем каждая III фаза клинических испытаний генерирует почти 6 миллионов точек данных, по сравнению с 3,6 миллионами в 2020 году и всего одним миллионом в 2012 году, однако большая часть этих данных остается недоиспользованной. В отличие от структурированных данных, собираемых в формах отчетов о случаях, данные из реальной клинической практики (real-world data, RWD) часто неполны и могут быть ненадежными с точки зрения репрезентативности и релевантности, что затрудняет их интеграцию и анализ в больших масштабах.
Перспективы RWD сталкиваются с сохраняющимися барьерами
Данные из реальной клинической практики (RWD) становятся все более распространенными по мере цифровизации здравоохранения и сбора информации далеко за пределами клинических испытательных центров. Глобальные регулирующие органы, такие как Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) и Европейское агентство по лекарственным средствам (EMA), оценили потенциал RWD, опубликовав рамочные документы, которые поощряют их ответственное использование при подаче заявок. Пандемия еще больше ускорила децентрализованные испытания и дистанционный мониторинг, выдвинув RWD в мейнстрим.
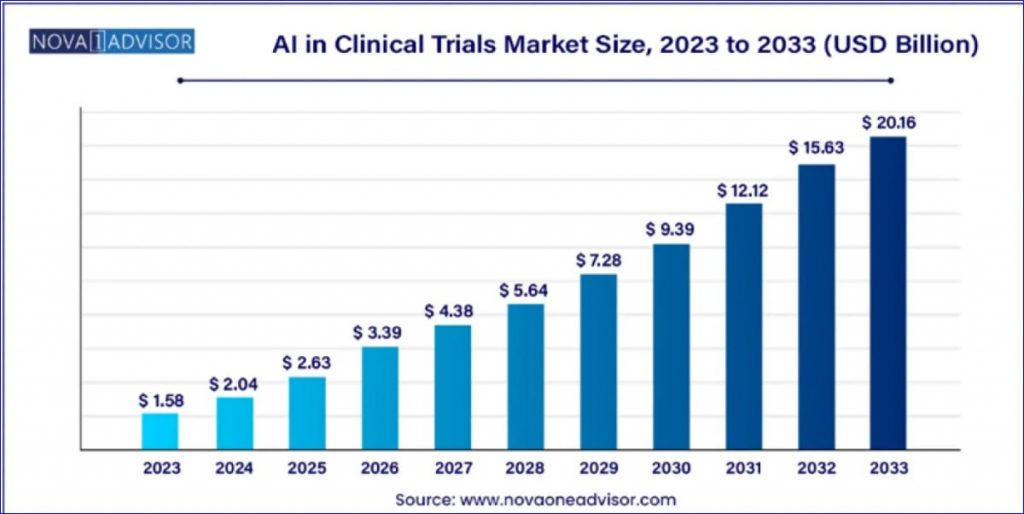
Тем не менее, интеграция по-прежнему носит фрагментарный характер: здесь — данные с датчиков, там — конвейер обработки электронных медицинских карт, что приводит к хрупким мозаикам систем, интерфейсов и этапов сверки. К распространенным проблемам относятся:
- Разрозненность и несовместимость данных: данные клинических испытаний, страховые выплаты, электронные медицинские карты, лабораторные анализы и другие источники часто поступают в несогласованных форматах с различными словарями, стандартами кодирования и уровнями детализации.
- Качество данных и предвзятость: данные из реальных источников могут содержать пропущенные значения, неполные результаты или предвзятость, связанную с неслучайным отбором пациентов, что ограничивает их использование в качестве самостоятельных доказательств и увеличивает риск ложных выводов.
- Операционные задержки: многие спонсоры запускают критически важные рабочие процессы на основе множества разрозненных решений, объединенных ручной очисткой и сверкой, что характеризуется трудоемкими запусками и остановками.
- Проблемы совместимости: Несмотря на прогресс в разработке глобальных стандартов, таких как Fast Healthcare Interoperability Resources (FHIR) и CDISC, их повсеместное внедрение остается фрагментарным, что делает интеграцию между системами медленной, дорогостоящей и подверженной ошибкам.
- Регуляторные препятствия: Обеспечение конфиденциальности пациентов, соблюдение требований к происхождению данных и демонстрация методологической строгости остаются проблемами. Глобальные исследования также сталкиваются с ограничениями, связанными с локализацией данных и согласием пациентов.
Аргументы в пользу стандартизированной гармонизации данных
Без строгой гармонизации данных в режиме реального времени перспектива использования данных из реальной практики и, в конечном итоге, ИИ, остается запертой в изолированных системах. Цель состоит не просто в увеличении объема данных, а в их улучшении. Гармонизация данных из реальной практики с традиционными данными клинических испытаний создает высокоточное представление об эффективности лечения как в контролируемых, так и в реальных условиях. Но это требует изменения подхода.
Внедрение стандартов, таких как CDISC и FHIR, с самого начала гарантирует согласованность потока данных на протяжении всего жизненного цикла исследования. Эта проактивная стратегия исключает дорогостоящую и подверженную ошибкам сверку данных на последующих этапах и обеспечивает аналитику в реальном времени, готовность к регулированию и получение аналитических данных на основе ИИ.
В отличие от этого, сегодняшняя норма параллельных конвейеров, объединенных постфактум, создает хрупкие интеграции и задержки. Ранняя гармонизация превращает данные из обузы в преимущество, закладывая основу для скорости, качества и доверия в клинической экосистеме, основанной на ИИ.

Искусственному интеллекту необходима новая инфраструктура данных
Искусственный интеллект уже меняет медико-биологические науки, от сортировки пациентов с помощью методов визуализации до оценки рисков. В разработке лекарств его потенциал огромен: предиктивное моделирование, синтетические контрольные группы, адаптивные схемы клинических испытаний и многое другое.
Однако эти инновации не решают основную проблему — операционные задержки. Клинические испытания по-прежнему длятся от 10 до 15 лет, и лишь небольшая часть этого времени тратится на сбор доказательств, таких как дозировка и измерение параметров пациентов. Остальное время уходит на запуск исследования, набор участников, обработку данных и подготовку документов для подачи.
Искусственный интеллект и гармонизированные данные потенциально могут значительно сократить сроки клинических испытаний и оказать существенное влияние. Например, клинические испытания III фазы обычно стоят около $36 млн, а некоторые превышают $100 млн, при этом почти 40% тратится на операционные расходы и накладные издержки.
Оптимизация рабочих процессов с помощью ИИ может принести немедленную и значительную отдачу от инвестиций. Помимо повышения эффективности, ИИ позволяет проводить более интеллектуальные исследования, используя синтетические контрольные группы и предиктивное моделирование для оптимизации набора участников и принятия решений по дизайну исследования. В конечном итоге, данные в реальном времени дополнительно поддерживают непрерывное обучение и адаптивный дизайн исследований, открывая путь к значительному ускорению их проведения. То, что сейчас занимает 12 лет, может быть сокращено до пяти или шести лет, если данные будут чистыми, интегрированными и надежными.
Создание экосистемы для исследований, основанных на ИИ
Для реализации этого видения отрасль должна перестроить свою инфраструктуру данных, включив в нее следующие ключевые элементы:
- Двунаправленный поток данных в реальном времени: Замените ночные пакеты потоковыми обновлениями, чтобы все заинтересованные стороны одновременно видели одну и ту же истину.
- Встроенная интеграция: Внедрите стандартизацию в ядро платформы, а не в качестве дополнительных модулей.
- Открытые стандарты: Избегайте зависимости от поставщика и обеспечьте межплатформенное сотрудничество.
- Конфиденциальность и происхождение данных: Сделайте деидентификацию и таблицы происхождения данных аудитного уровня обязательными условиями для ответственного повторного использования.
Истинный потенциал ИИ заключается в превращении клинических разработок из узкого места в двигатель производительности для здоровья человека. Процесс разработки лекарств уже ускоряется, поскольку ИИ выявляет тысячи новых путей лечения, но каждая прорывная идея должна пройти все этапы клинических испытаний — от I до III фазы. Благодаря оптимизации клинических разработок и переосмыслению инфраструктуры данных, отрасль может увеличить пропускную способность конвейера разработки и масштабировать персонализированную медицину.
Влияние унификации данных на результаты бизнеса
Теория и концептуальное мышление по своей сути являются амбициозными, и большинство спросит: как это может или уже помогает спонсорам сегодня? На основе недавнего тематического исследования, представленного на DPHARM 2025, ведущий фармацевтический спонсор, используя унифицированную стратегию данных, смог добиться значительного влияния на бизнес-процессы, пропускную способность конвейера разработки и бизнес-аналитику.
Устранение параллельных потоков данных и создание единого источника достоверной информации для всех заинтересованных сторон, от управления данными и клинических операций до биостатистики, медицинских и групп безопасности, позволяет спонсорам достичь следующих результатов:
- Ускорение подачи заявок в регулирующие органы: Благодаря данным, уже гармонизированным в соответствии с CDISC и имеющим подтвержденную аудиторскую достоверность информацию, спонсор может выполнять сборку SDTM/ADaM, производство TLF и упаковку eCTD в непрерывном, а не эпизодическом режиме.
- Получение оперативной и научной информации в режиме реального времени: Замена пакетной обработки единой двунаправленной системой передачи данных позволяет спонсору получать оперативное представление об операционной эффективности и проводить научный анализ по запросу.
- Увеличение объема данных по безопасности и HEOR: Объединение данных клинических испытаний с электронными медицинскими картами, данными страховых компаний и регистрами укрепляет фармаконадзор и расширяет базу данных за пределы исследовательского центра.
- Ускорение запуска исследования: Благодаря библиотекам протоколов, графиков мероприятий и eCRF, основанным на стандартах, в сочетании с интеграцией с FHIR, спонсор может сократить сроки оценки осуществимости и активации исследовательских центров.
- Основа для инноваций в области ИИ: Благодаря объяснимой, проверяемой и воспроизводимой основе для ИИ, команды могут безопасно внедрять высокоэффективные сценарии использования ИИ, не перенастраивая данные для каждого проекта.
Заключение: От узкого места к прорыву
Будущее клинических испытаний не просто быстрее, оно умнее. Но только если мы начнем с высококачественных, гармонизированных данных. ИИ не может исправить неисправные входные данные. Как напоминает нам поговорка: что на входе, то и на выходе. Чтобы трансформировать клиническую разработку, мы должны сначала трансформировать подход к управлению данными. Это означает проектирование с приоритетом стандартов, гармонизацию в реальном времени и единую экосистему, созданную для скорости, масштабируемости и научной строгости.
Только тогда ИИ сможет выполнить свои обещания и открыть новую эру генерации доказательств, разработки лекарств и здравоохранения.
Источник: https://www.pharmexec.com/
Источник: https://www.gminsights.com/
Источник: https://credevo.com/
25.12.2025